Helpfeelでの質問文の半自動生成の取り組み 後編
ChatGPT API登場前から研究していた話
目標: このあたりを共有する
自然言語の良質な言い換えの難しさ
非MLエンジニアとしての挑戦過程で得たもの
これまでに試した手法
古典的なNLP手法いろいろ
BERT
文章を文頭と文末の双方向から学習可能な自然言語処理モデル
文脈を理解できる
T5 (Text-to-Text Transfer Transformer)

NLPの研究室を訪問して教えてもらった
テキスト生成モデル
BERTでの言い換えタスク
基本的な穴埋め問題
類義語を用いた質問文の機械展開
言い換えたい部分を
[MASK] にする わずかに文脈を与える
例

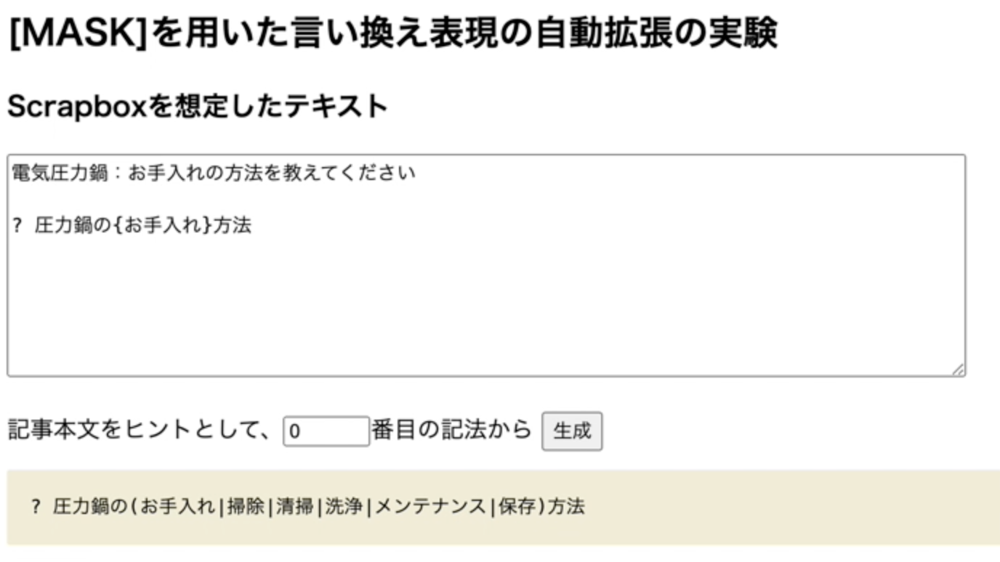
課題
単語レベルでの言い換えしかできない
文脈情報と言い換え対象の単語を人間が指定する必要がある
T5での言い換えタスク
事前学習済みのモデル
100GBほどの日本語テキストで訓練されている
転移学習のためのサンプルコード
例: Input: 料理に入っているアレルギー物質が知りたい
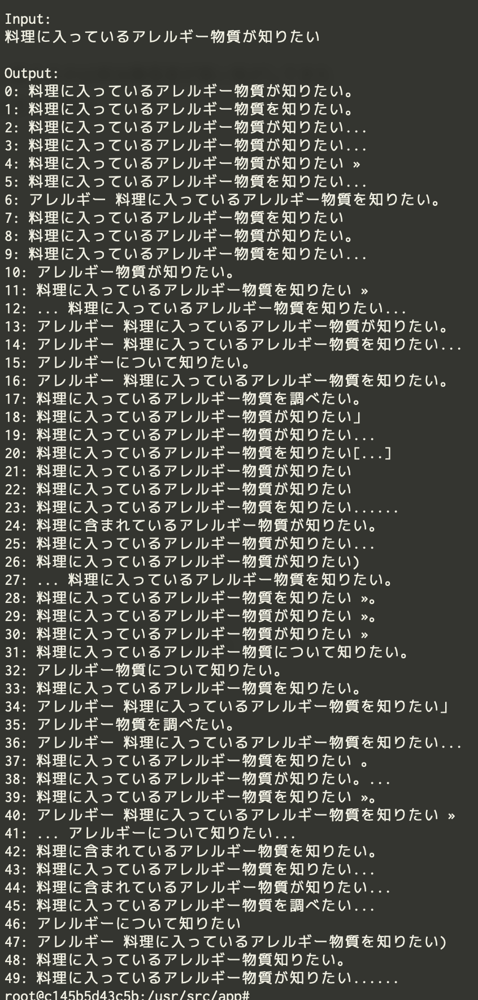
課題
期待したほどバリエーションがない
本質的でない箇所の言い換えが多い
出力される日本語が安定していない
T5モデルをfine tuning
テクニカルライターによる既存の言い換えデータを使ってfine tuning
理想とする入出力のペアを与える
生成結果の精度が明らかによくなった
初代のプロトタイプができた
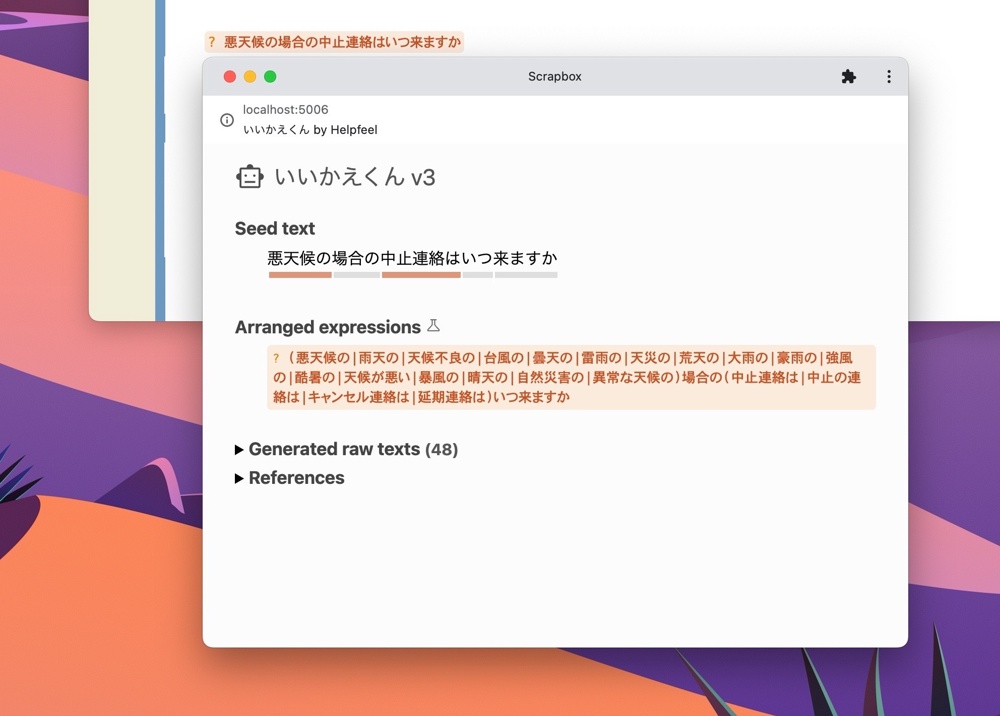
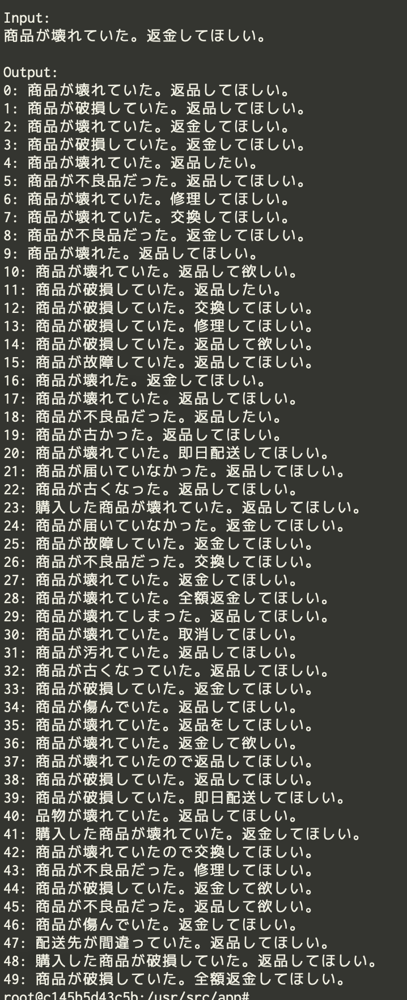
成果例: Before / After
Input: 商品が壊れていた。返金してほしい。

Input: フリーローンの繰り上げ返済をしたい

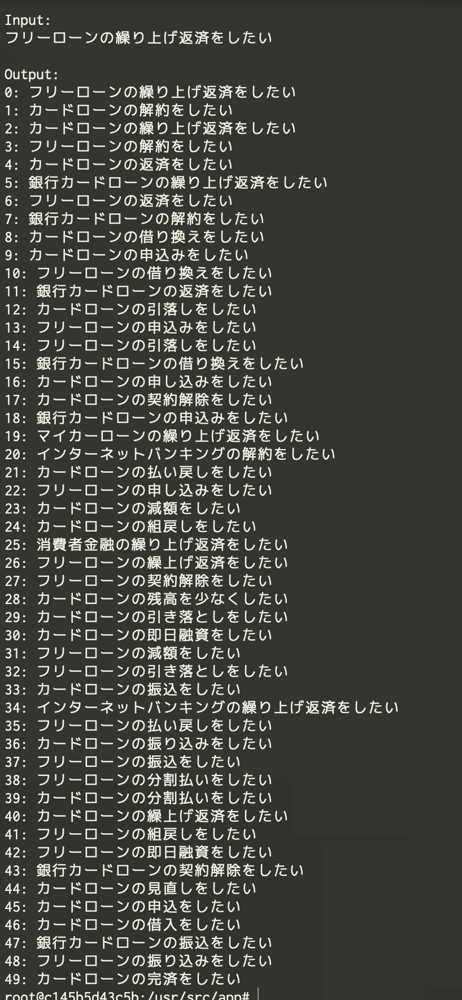
課題
業界ごとにfine tuningするの?
クリエイティビティが足りない
ChatGPT API 登場
障壁となっていた問題がほぼ解決
生成される文章の調整と精度保証
→ プロンプト調整
題材ごとのファインチューニング
→ 基盤モデルが優秀なので当面は不要
さらに、使いやすい!
→ REST API呼び出しだけでよい
チャンス到来
もどる