NLP2024 3日目
聴講した発表をいくつかピックアップ
適宜加筆修正します

Common Crawl
ウェブサイトを巡回・収集し、無償で提供してくれている
WET
テキスト抽出結果が格納されているがちょい扱いづらい
WARC
こっちを使った
ウェブページのURIがわかれば期間を指定してだウンロードできる
AWS S3のリンクだ
テキスト抽出
HTMLを取り出す
言語判定
日本語かそれ以外かを予測する二値分類器
これくらいならEmbeddingまで使わなくて大丈夫
Wikipedia CirrusSeaechの多言語テキスト(1/2だけ使用)
fastTextのほうが精度・速度面で優れていた
いまから作るならこっちを使うと良いとのこと
テキスト抽出をここなわずに日本語で書かれている可能性が高いウェブページだけを選ぶ
95%くらいは英語なので早めに除外したい
英語も取っておけばいいのでは? → 英語はもっといいコーパスがあるのでそっちでやる
本命の5%だけに集中して高速化、計算リソースの節約
なるほど 
ヒューリスティックに判定
html lang="ja"
titleタグの中身に対して精密な日本語判定を適用した結果、日本語であるとする
適合率 0.888 再現率 0.967
できるだけrecallを上げたほうがいい
いま振り返ると「ひらがなを含むか否か」の判定が良かったのではないかとのこと
初期のHelpfeelでもこの判定基準が便利で使いがちだった気がする
繰り返しの多いウェブページを除去する
ECサイトなどで商品を列挙しているだけの可能性がある
品質の低そうなテキスト、有害な表現を含む可能性のあるページを除去する
重複したテキストは学習しないほうがいい
過学習の防止
オリジナルコンテンツに寄りすぎてしまう事象の回避
MinHashで重複文書を検出できる
古い方を除去して新しい方を採用
質の高い日本語オリジナルのインストラクションを作成
2000万円くらいかかると推定
企業との共同研究で費用を捻出
最大約70名のアノテーターで作成
作成しながら使用を固めていく。タグ種類を検討しながら付与
データ作成の進捗
Alpaca, Doliyをもとにした問題 350
様々なQAサイトをもとにした問題 550
Web上の「GPTを使ってみた」の例 100
コミュニティQAサイトの質問をもとにした質問
要約、翻訳、校正、抽出など、足りない種類のデータ
データに対するタグ付与
操作タグ
質問がどのような操作を求めているものか
14種類くらい
数学やプログラムもある
主観/客観、時間依存
質問の回答が特定の時間に依存しているか
安全性
今後
データをさらに増やす
マルチターン
画像ドキュメント(チラシ)などの情報
大規模言語モデル Swallow
Llama 2ベース
英語の言語資源を日本語LLMの構築に活用したい
日本語LLMの構築に英語も役に立つのでは?
英語で学習済みのLLMを、日本語テキストを主として事前学習を継続する
語彙拡張による日本語テキストの学習・推論効率の改善
Q: 英日翻訳のタスクが性能落ちたということは、オリジナルのモデルを壊してしまった可能性がある?
継続事前学習では新たにデータを加える際にこれまでのデータも含めながらやっていくと上手くいきやすいらしい?
近年、論文におけるWebリソースの参照が増えてきている
文献タグ(
...ら[1] のようなやつ)よりもURLでの直接参照が与えられることが増えてきた 論文の執筆、査読支援
本来引用元を示すべきところで忘れられていないか
既存手法の判定の再現性が低い
URL引用に特有の言い回しへの対応が課題
We used ~ とか
引用要否判定
文単位で、必要・不要の二値分類問題を解く
Sentence Classification(SC)
判定対象の文のみを文脈埋め込みモデルに入力
各クラスのlogitsを得る
Sentence Pair Classification(SPC)
判定対象の文 + 前後の文を文脈としたものを入力
3つのぶんを
[SEP] で結合したもの 関連研究
SEPID-cite
Word2VecとCNNを用いた手法
ACL-cite
文脈情報を多く与える
PMOA-cite
医学分野の論文データセット(PubMed)を利用
論文PDFのテキスト化
PDFNLT-1.0 を使用
試してみよう
文の分割
Spacyのen core web lgを使用
実験結果
文献タグ: SCでもそれなりにいける
URL: できるだけ広い文脈でSPC するほうがよい
大規模なウェブベースの日英対訳コーパスを構築する
JParaCrawlコーパスの拡大
JParaCrawl v4.0 を作った
4400 万文以上を含む
Common Crawl
最近のWebサイト、小規模な対訳Webサイトが含まれない
Common Crawl に含まれていないWebサイトも使いたい
クラウドソーシングの活用
日英対訳が含まれていそうなページを募る
「あなたが知っているサイトを教えて」というシンプルなタスク
多くの個人に聞くことによりニッチなサイトも効率よく発見できる
翻訳精度の自動評価
BLEU
COMET
人手評価との相関が高い
19のテストセットのうち英日では16、日英では17のテストセットで以前のJParaCrawl を上回る精度を達成
懇親会で教えてもらった
文法誤り訂正(GEC)
文書校正や言語学習支援への応用が可能
n-gramの出現頻度に基づいてF値を計算する手法
単語の出現の差をベン図で表現
ベン図の重なり合った各領域に含まれるn-gramを訂正とみなす(7種類)
削除、挿入、保持
埋め込み表現を用いた手法よりも精度が良い
大きな計算量を必要とせずに目的達成できる
スポンサーブースの様子
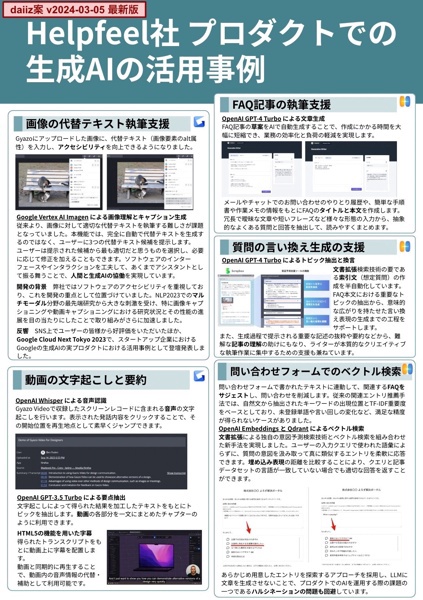
株式会社Helpfeelはプラチナスポンサーとして協賛しています
各プロダクトでの生成AIの活用事例をまとめた新作ポスターを作りました 


Gyazo
画像の代替テキストの執筆支援
動画の文字起こしと要約
Helpfeel
マイナビ連載 第10回: 検索に溶け込むAI
Scrapbox
今回は掲載できませんでしたが研究開発が進行中です。お楽しみに!
デザイナーの さんがすごい
さんがすごい
私の原案(左)がこんなにも綺麗な作品(右)に化ける
 →
→ 
背景色がうっすらグラデーションしていて生成AIサービスっぽさがある!
旅日記
会場近くのコンビニを把握した
昼食
ビュッフェ

デザート判定の二値分類のためのデータセットプレート
懇親会
ホテルのレストラン


駅出てすぐ。灯台下暗し。
一人で参加したので会場内の初心者ツアーがありがたかった
研究の詳細話を聞けて面白かった。皆さん説明がうまくて勉強になることが多すぎる。
個人開発で扱いに迷っていた研究的な話題も相談できた
Twitterで見たり知人から聞いたりして、以前からずっと気になっていた