Vertex AI ベクトル検索を使ってみる
daiiz
Heplfeel アーキテクト
ウェブアプリケーションエンジニア
作家活動
生成AIと向き合う新刊を2種類出した


ソフトウェア作家活動
画像を使った画像検索


検索
仕事でも個人開発でも毎日考えている
本日お見せするのは、個人開発のものです
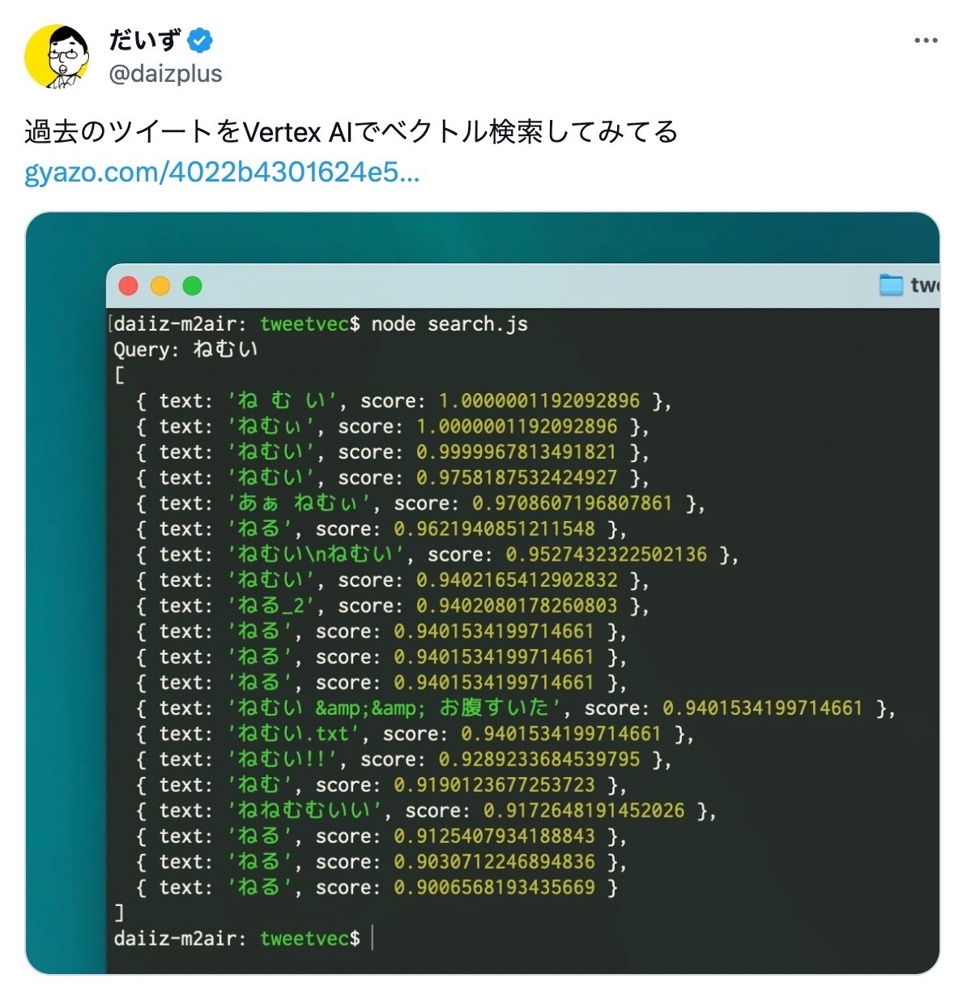
ベクトル検索したい
生成AIブーム
質の良いEmbeddingが手に入るようになった嬉しさ
ベクトル検索
Elasticsearch
MongoDB
Qdrant
Vald
NGT
気楽に実験したい
ローカル環境
セットアップが大変
軽量なベクトルDBを使う手はある
デモ環境
最小構成の価格が高め
実験ごとに課金していくと厳しい
こういうものを勢いよく作りたい

仕組み
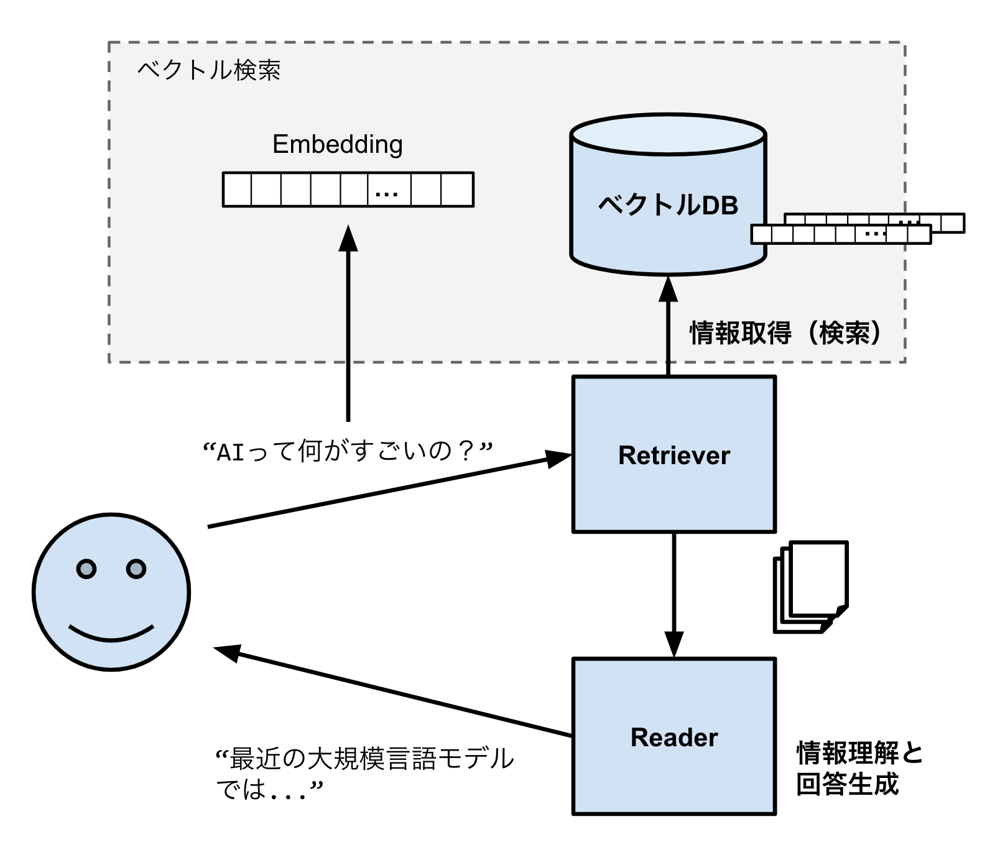
複数の実験で共用できるベクトルDBを用意しよう!!
Vertex AI Matching Engine
GCPのAI系サービスの総称
Matching Engine
ベクトル検索エンジン
最近「ベクトル検索」に改名したらしい?

ハマりポイントとか、すごさとか、話します
作業記録
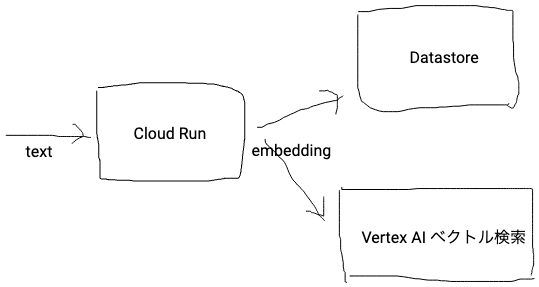
構成
Datastoreとベクトル検索インデックスに同時に書き込む
ベクトル化(Embeddingへの変換)
text-embedding-ada-002 API(OpenAI)
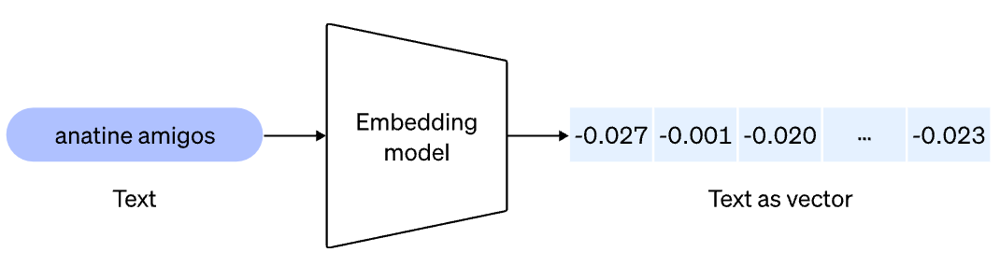
1635次元
PaLM 2 API(GCP)
768次元
データの取り込み方法
2つの方式から選べる
バッチ更新(BATCH_UPDATE)
ストリーミング更新(STREAM_UPDATE)
運用中の検索インデックスに対して追加・削除できる
REST APIとして呼び出せる
データの永続化
ベクトル検索はあくまでインデックス
作って壊すことに耐えられるようにしておくべし
永続化は別のDBでやる
Elasticsearchのインデックスの運用方法と似ている
IndexとIndexEndpoint
Index
ベクトル(datapoint)を蓄積して最近傍探索する
更新系の処理はこっちにリクエスト
IndexEndpoint
Indexの探索処理を呼び出せるようにする
取得系の処理はこっちにリクエスト
手順
① Index の作成
② IndexEndpoint の作成
③ Index を IndexEndpoint にデプロイ
Indexの作成
config.json{ "display_name": "demo_202312_6", "metadata": { "contentsDeltaUri": "gs://daiiz-demo-index/data/", "config": { "dimensions": 1536, "approximateNeighborsCount": 100, "shardSize": "SHARD_SIZE_SMALL", "algorithm_config": { "treeAhConfig": {} } } }, "indexUpdateMethod": "STREAM_UPDATE"} contentsDeltaUriでCloud Storageを紐付ける(必須)
初期データを入れておく
JSONやCSV形式で記述
注意: 30~60分くらいかかる
結構待ち時間がある
初期データが1件でもこれくらいかかる
なんでだろう
設定ミスが判明するまでにも時間がかかる
試行錯誤するときは十分余裕をもって挑むとよい
注意: 初期データ0件はだめ
ストリーミング更新であっても
仮のデータを入れておこう
Indexデプロイ処理の最終段階でエラーになる!!
Indexの更新
datapointの追加・更新
jsconst datapoints = [ { datapoint_id: "ID", feature_vector: [...], restricts: [] }]jsconst apiUrl = `https://us-central1-aiplatform.googleapis.com/v1/${indexId}:upsertDatapoints`
await fetch(apiUrl, { method: "POST", headers: { "Content-Type": "application/json", Authorization: `Bearer ${token}`, }, body: JSON.stringify({ datapoints }),});嬉しさ: idを指定できる
探索結果の datapoint.id を直接メインのDBと照合できる
idの対応関係を保持する必要がない
効率的にupsertできる
嬉しさ: 追加後すぐに検索できる
ストリーミング更新であっても即検索可能
すごい
Indexを検索
クエリベクトルに対する最近傍探索
jsconst queries = [{ datapoint: { datapoint_id: "0", feature_vector: embedding, restricts: [] neighbor_count: 10, },]jsconst apiUrl = `${googAiApiOrigin}/v1/${indexEndpointId}:findNeighbors`
const res = await fetch(apiUrl, { method: "POST", headers: { "Content-Type": "application/json", Authorization: `Bearer ${token}`, }, // FindNeighborsRequest body: JSON.stringify({ deployed_index_id: "INDEX_ID", queries, }),});うまくいっていそう
嬉しさ: restrictsが便利
これが最高
複数のデモアプリを同居できる
App=demoapp かつ User=daiiz であるdatapointを対象に探索する
js [ { "namespace": "App", "allow_list": ["demoapp1"] }, { "namespace": "User", "allow_list": ["daiiz"] }, ] さらに
deny_listもある
注意: 追加後すぐにはベクトル数の情報は変わらない
値に変化がなくても気にしなくてOK
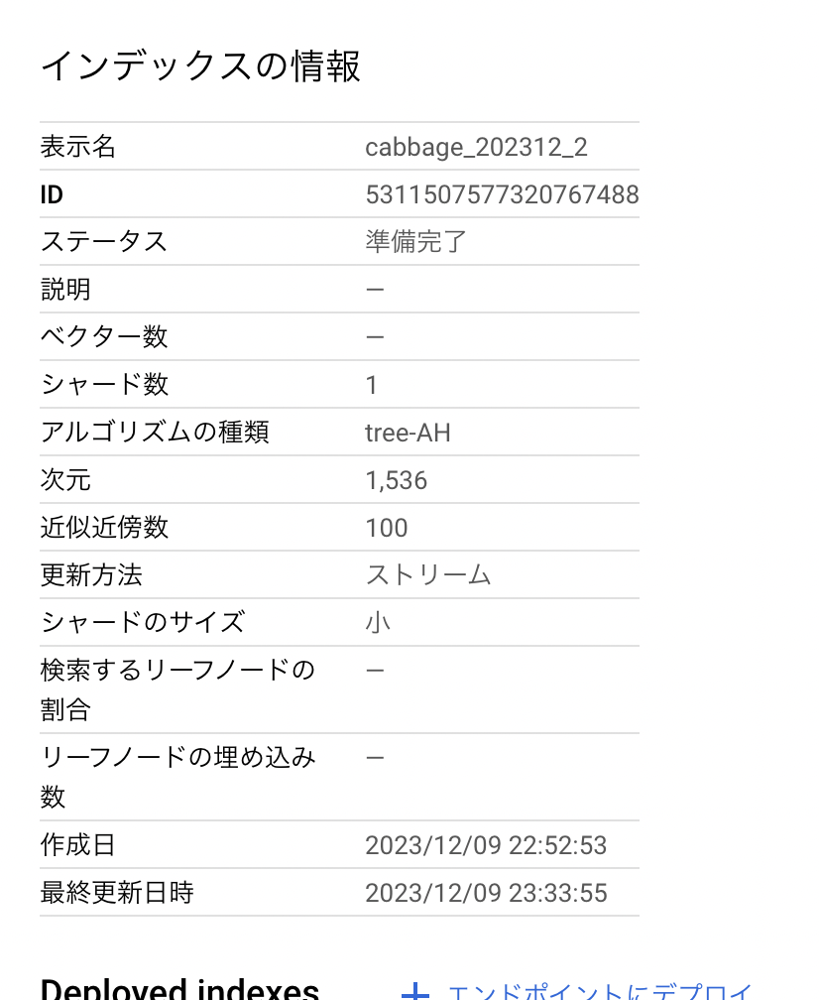
実際に検索してみれば確認できる
定期的にベクトル空間の最適化が行われるらしい
特に何も設定せずに完了メールが来た
ストリーミング更新でも効率的な検索ができる
正しいベクトル数が表示された
コスト感

約300円/日
Indexがデプロイされているだけで発生する金額
ちょっと高い!!!
これに加えて
Index Building
Index Streaming Update
いまのところ少額だが、もう少し使い込んでみないとわからない
自分のツイートを全部取り込んでみた
デモ公開、間に合わず(今週中になんとか!)